When should you use Azure Databricks?
Once upon a time, Sql Server was our central tool for data management, for both OLTP (online transactions processing) or OLAP(online analytical processing) database systems.
We have used Sql Server Agent Jobs to pull the data from FTP or any other source. We have used Sql Server stored procedures to pull the data into the Staging database. We have used Sql Server stored procedures to enrich and aggregate the data. And we have used Sql Server as a data serving layer.
These days we need to consider utilizing various cloud services. Attempts to lift and shift existing systems into the cloud often end up being quite expensive if we tend to keep Sql Server taking care of all data pipeline stages.
There are multiple great services in the Azure cloud and Microsoft tends to build each product with multiple features allowing it to take care of multiple pipeline stages. This does not mean that we need to go back to the monolith architecture, let's find out where each service fits.
Data Factory can pull the data from any source, orchestrate the flow, and enrich and aggregate the data.
DataBricks can pull the data from any source, orchestrate the flow, enrich and aggregate the data, serve the data from data lakehouse and visualize it using dashboards.
Synapse Analytics with integrated pipelines can pull the data from any source, orchestrate the flow, enrich and aggregate the data and serve the data.
PowerBI can pull the data from any source, enrich and aggregate the data and serve and visualize the data.
Sql Managed instance can pull the data from any source, enrich and aggregate the data and serve the data.
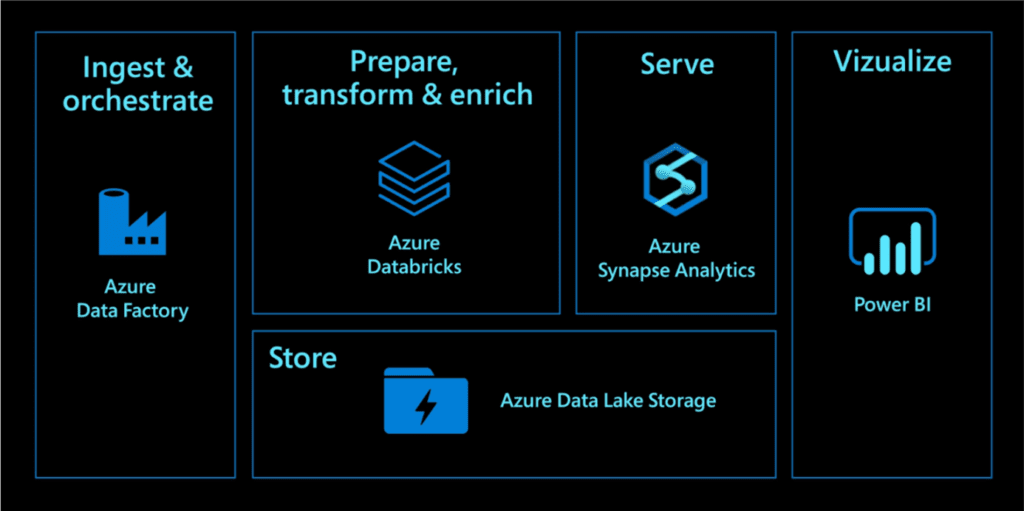
In the above image, we can see where Microsoft positions each of the abovementioned cloud services and how Azure services can be used as a lego piece to build the data warehouse pipeline architecture.
Azure Data Factory should be used as an ingestion and orchestration service. Load data from external or internal sources and store it in the Azure Data Lake Storage.
Azure Data Lake should be housing data of all types, except data used for online transaction processing.
Azure Databricks's purpose is to prepare, transform, enrich and train datasets.
Azure Synapse's purpose is to serve clean aggregated data from Azure Data Lake Storage.
Power BI will be a visualization layer, reading data off the Azure Data Lake storage or Azure Synapse Analytics and generating analytical reports and dashboards.
Sql Managed Instance is not in the above image because its too expensive to be used in data warehousing architecture. Sql Server's purpose is to take care of online transaction processing, store and serve relational data and support high amounts of inserts, updates and deletes while making sure the data is consistent. This is a very difficult zone, therefore, this service price is quite high.
Can be great to hear your opinion or observations in the comments...


Comments
Post a Comment