Doing things right or do right things? How to find row count of every table in database efficiently.
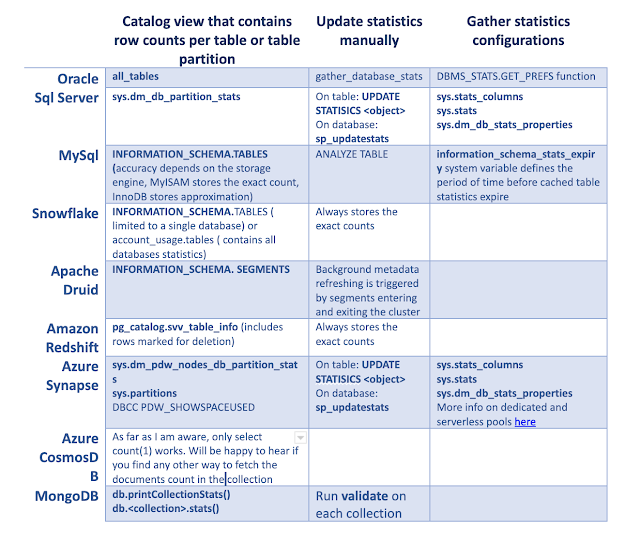
One Data Engineer had to replicate data from one well-known database vendor to a less-known database vendor. He used select count(*) to validate that tables row counts were equal on the source and target. It worked so slowly, that he got fired without ever knowing whether the table's content was equal or not. Often laziness is a first step towards efficiency. Rather than doing count(*) on each table, the unfortunate DBA could have used internal statistics that every decent database vendor is maintaining, stored in the system views. Need to take into consideration that it will never be 100% accurate and will depend on a few things How often do database objects change What is the internal or manual schedule for statistics refresh. For a lot of database vendors, statistics will get refreshed automatically only when the changed data is more than 10% of the total table rows but this is usually configurable per table. The percentage of rows used to calculate the statistics. The most accu...




