I am a Data Platform Microsoft MVP and a technology expert with more than 20 years of experience, a community leader with a profound knowledge of Microsoft products and services, while also being able to bring together diverse platforms, products, and solutions, to solve real-world problems.
I have a hands-on experience managing various data management technologies in Azure, AWS and Google public cloud platforms, including SQL Server, Azure CosmosDB, AWS DynamoDB, MemSQL, MySQL, Postgres,Snowfla
I'm moving !!!!!
Get link
Facebook
X
Pinterest
Email
Other Apps
-
I am truly exited to move this blog to SQLblog.com !
" You cannot create a Microsoft capacity using a personal account. Use your organizational account instead." What a disappointment and frustration! I've been trying to set up Microsoft Fabric for a while now and figure out how to work around this error. I use my personal Gmail for an MVP subscription to learn and experiment with Azure services. When I visit app.fabric.microsoft.com and try to use my private Gmail address, I keep getting a similar message: It's frustrating because I'm eager to dive into Fabric and explore its capabilities. I would get the same error trying to set up Azure Data Catalog, PowerBI embedded, and more. What are the different account types and how do they differ? A work or school account is created through Active Directory or other cloud directory services, such as Microsoft 365. On the other hand, a personal account is one that's manually created for individual use, consisting simply of a username and password. After digging into ...
Did you know that Snowflake is working on integrating Microsoft Azure Open AI service? Companies that use Snowflake as their Data Warehousing solution, can now use Azure Open AI through Snowflake CortexAI - Snowflake's managed AI services. This is available not only to Snowflake clients using Snowflake on Azure. Clients from any cloud and any region can now build AI-powered apps or data agents. Open AI models will run within the security boundaries of the Snowflake data cloud, providing unified governance, access controls and monitoring. Even more interesting: there will be the opposite collaboration as well. Cortex AI agents will be available from within Microsoft Teams Copilot and Microsoft 365 Copilot so users can interact with their data stored in Snowflake using natural language. This integration will become generally available in June 2025
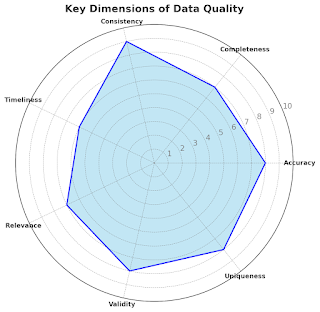
Imagine, you are baking a cake. You have all the ingredients except eggs. Of course, you could improvise but most probably instead of the moist chocolate cake, you end up with a dry science experiment. Incomplete data leaves everyone unsatisfied. During the decision-making party, every data quality dimension is an important guest with a unique vibe: Good Data should be C omplete , when all data attributes, that describe data in its fullness, are present as a part of your data. This guest keeps the party snacks stock full and makes sure no one gets hungry. Incomplete data leads to half-baked insights. Good Data should be Accurate . This means that the data correctly describes its objects and accurately reflects the reality. This party guest is a perfectionist, checking that the playlist is perfectly chosen. Good Data should be Timely . This means that the data is fresh. No one wants to eat last week's sushi. It's not only unappetizing; it is downright risky. This guest makes sur...


Comments
Post a Comment