Understanding the Pillars of Data Quality
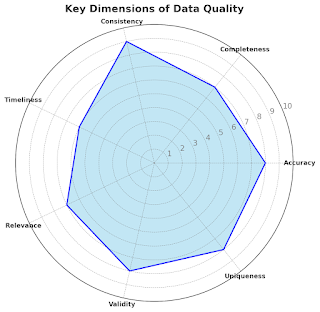
Imagine, you are baking a cake. You have all the ingredients except eggs. Of course, you could improvise but most probably instead of the moist chocolate cake, you end up with a dry science experiment. Incomplete data leaves everyone unsatisfied. During the decision-making party, every data quality dimension is an important guest with a unique vibe: Good Data should be C omplete , when all data attributes, that describe data in its fullness, are present as a part of your data. This guest keeps the party snacks stock full and makes sure no one gets hungry. Incomplete data leads to half-baked insights. Good Data should be Accurate . This means that the data correctly describes its objects and accurately reflects the reality. This party guest is a perfectionist, checking that the playlist is perfectly chosen. Good Data should be Timely . This means that the data is fresh. No one wants to eat last week's sushi. It's not only unappetizing; it is downright risky. This guest makes sur...
